In 2025, Python remains the undisputed language of choice for data science, machine learning, and AI-driven development. Its clean syntax, extensive community, and unmatched ecosystem make it indispensable for everything from simple data wrangling to large-scale deep learning deployment.
But the Python landscape is evolving—fast. New libraries emerge.Existing ones grow more powerful. And developers are constantly looking for tools that can do more, faster, and with fewer lines of code.
Whether you’re building AI-powered analytics, training LLMs, or deploying predictive models to production, the libraries you choose will define your efficiency, performance, and success.
At Fyld, we help organizations design smart data and AI pipelines—combining the right technology with future-proof architecture. Here’s our curated list of the most relevant and powerful Python libraries shaping the field in 2025.
Why Python Still Leads in AI & Data Science in 2025 Edition
Python’s dominance isn’t accidental — it’s the result of over a decade of momentum, constant evolution, and an ecosystem tailored to innovation. And in 2025, its relevance is only growing.
Here’s why:
- Simplicity and readability: Python’s syntax remains one of its biggest strengths. It’s beginner-friendly, but robust enough for complex AI systems.
- Extensive ecosystem: From NumPy and pandas to TensorFlow, Hugging Face, and LangChain, Python has a solution for every stage of the ML pipeline.
- Interoperability: Python integrates seamlessly with notebooks, cloud platforms (AWS SageMaker, Google Vertex AI), and deployment stacks like FastAPI and Docker.
- Community-driven development: Most libraries are open source and actively maintained—meaning constant improvement and real-time adaptation to trends.
- Built for innovation: Emerging fields like AutoML, edge AI, federated learning, and LLM orchestration are all evolving first in the Python ecosystem.
According to the Stack Overflow Developer Survey 2024, Python remains the most used language in data science, and the third most loved overall—just behind Rust and TypeScript.
1. NumPy
What it is
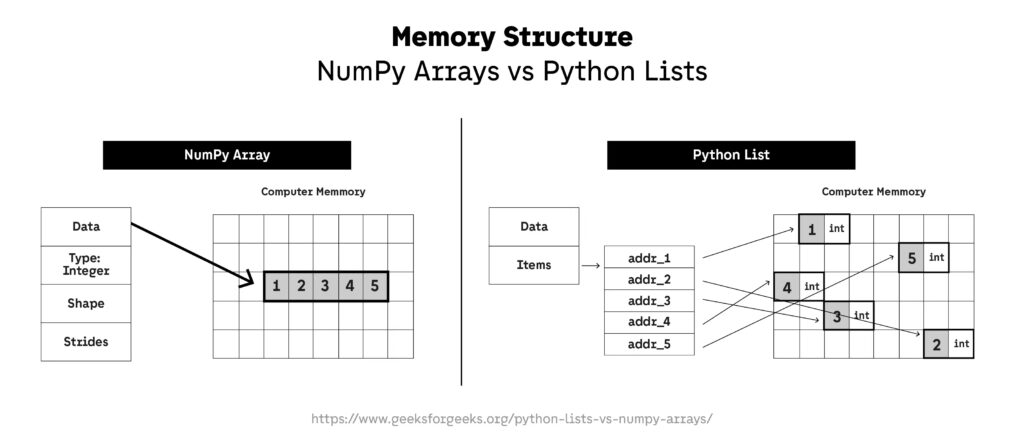
NumPy (Numerical Python) is the foundational package for scientific computing in Python. It provides n-dimensional array objects, linear algebra routines, statistical functions, broadcasting capabilities, and vectorized operations that make it lightning fast compared to native Python lists.
Why NumPy Still Matters in 2025
While newer libraries have emerged, NumPy remains the underlying engine powering nearly every numerical computing and machine learning tool in the Python ecosystem—including pandas, SciPy, Scikit-learn, TensorFlow, and PyTorch.
In 2025, NumPy continues to evolve in two major directions:
- Performance: NumPy 2.0 has further improved memory usage and now supports better parallelism and SIMD (Single Instruction Multiple Data) capabilities.
- Hardware acceleration: Integration with GPU-based frameworks like CuPy and Intel’s oneAPI enables developers to seamlessly offload heavy numerical computations to modern hardware.
Use Cases in AI & Data Science
- Matrix operations for machine learning algorithms
- Feature scaling, normalization, and statistical transformations
- Preprocessing image and sensor data for deep learning
- Foundations for high-speed numerical simulations
You can learn more about useful NumPy techniques here and explore its case studies here.
Real-World Example
A notable application of NumPy was in the creation of the first-ever image of a black hole by the Event Horizon Telescope (EHT) collaboration. The EHT team utilized NumPy for handling large numerical datasets and performing complex calculations essential for image reconstruction. This monumental achievement showcased NumPy’s capability in processing vast amounts of astronomical data efficiently.
2. pandas
What it is
pandas is an open-source Python library providing high-performance, easy-to-use data structures and data analysis tools. It introduces two primary data structures: Series (one-dimensional) and DataFrame (two-dimensional), which are built on top of NumPy. These structures are designed for handling and analyzing structured data efficiently.
Why pandas Remains Indispensable in 2025
Despite the emergence of newer libraries, pandas continues to be a cornerstone in data analysis due to its versatility and integration capabilities. Key strengths include:
- Comprehensive Data Handling: Supports a wide range of data formats, including CSV, Excel, JSON, and SQL databases.
- Robust Data Manipulation: Offers functionalities for data cleaning, transformation, merging, and aggregation.
- Time Series Analysis: Provides extensive tools for time series data, including date range generation and frequency conversion.
- Integration with Other Libraries: Seamlessly works with libraries like NumPy, Matplotlib, and Scikit-learn, enhancing its analytical capabilities.
Recent updates have focused on improving performance, memory usage, and introducing new features like nullable data types, enhancing its utility in modern data workflows.
Use Cases in AI & Data Science
- Data cleaning and preprocessing for machine learning models.
- Exploratory data analysis (EDA) to uncover patterns and insights.
- Time series forecasting in finance and economics.
- Data transformation and feature engineering for predictive modeling.
See more about the good and the bad of using pandas here.
Real-World Example
Netflix utilizes pandas as part of its data analysis toolkit to analyze viewer data. By processing and analyzing this data, Netflix can recommend shows and movies tailored to each user’s preferences, enhancing user experience and engagement.
3. Scikit-learn
What it is
Scikit-learn is a robust, open-source Python library that provides simple and efficient tools for data mining and machine learning. Built on top of NumPy, SciPy, and Matplotlib, it offers a range of supervised and unsupervised learning algorithms through a consistent interface.
Why Scikit-learn Is a Staple in 2025
Scikit-learn continues to be a go-to library for machine learning due to:
- Wide Range of Algorithms: Includes tools for classification, regression, clustering, dimensionality reduction, model selection, and preprocessing.
- User-Friendly API: Offers a consistent and straightforward interface, making it accessible for both beginners and experienced practitioners.
- Integration with Other Libraries: Works seamlessly with pandas for data manipulation and Matplotlib for visualization.
- Community and Documentation: Backed by a strong community and comprehensive documentation, facilitating learning and troubleshooting.
Recent developments have focused on enhancing performance, expanding algorithm support, and improving integration with other tools in the Python ecosystem.
Use Cases in AI & Data Science
- Developing predictive models for classification and regression tasks.
- Clustering analysis for customer segmentation.
- Dimensionality reduction for data visualization and noise reduction.
- Model evaluation and selection using cross-validation techniques.

Real-World Example
The Event Horizon Telescope (EHT) project, which captured the first image of a black hole, utilized Scikit-learn for data analysis tasks. The library’s machine learning algorithms assisted in processing vast amounts of astronomical data, contributing to this groundbreaking achievement.
4. TensorFlow 2.x
What it is
TensorFlow 2.x is an open-source machine learning framework developed by the Google Brain team. It provides a comprehensive ecosystem for building and deploying machine learning models across various platforms, including desktops, mobile devices, and the cloud. TensorFlow 2.x emphasizes ease of use, offering intuitive APIs and seamless integration with Keras for rapid model development.
Why TensorFlow 2.x Matters in 2025
TensorFlow 2.x continues to be a leading choice for machine learning practitioners due to:
- Eager Execution: Operations are executed immediately, making debugging and development more straightforward.
- Keras Integration: Tight integration with Keras simplifies model building and training processes.
- Scalability: Supports distributed training across multiple GPUs and TPUs, facilitating large-scale model training.
- Deployment Flexibility: Models can be deployed on various platforms using TensorFlow Serving, TensorFlow Lite, and TensorFlow.js.
Use Cases in AI & Data Science
- Deep learning model development for computer vision, natural language processing, and time series analysis.
- Deployment of machine learning models in production environments.
- Research and experimentation with cutting-edge machine learning techniques.

Real-World Example
Google’s Smart Compose feature in Gmail utilizes TensorFlow to provide predictive text suggestions, enhancing user productivity. The model was trained using TensorFlow and deployed at scale to serve millions of users.
5. PyTorch
What it is
PyTorch is an open-source machine learning library developed by Meta AI. It offers dynamic computational graphs and a Pythonic interface, making it a favorite among researchers and practitioners for developing deep learning models. PyTorch’s flexibility and ease of use have contributed to its widespread adoption in academia and industry.

Why PyTorch Is a Staple in 2025
PyTorch maintains its prominence in the machine learning community due to:
- Dynamic Computation Graphs: Allows for real-time graph construction, facilitating intuitive model development and debugging.
- Strong Community Support: A vibrant community contributes to a rich ecosystem of tools and libraries, such as TorchVision and TorchText.
- Research Adoption: Widely used in academic research, leading to rapid implementation of state-of-the-art models.
- Production Readiness: Features like TorchScript and TorchServe enable seamless transition from research to production.
Use Cases in AI & Data Science
- Development of deep learning models for computer vision, natural language processing, and reinforcement learning.
- Academic research and experimentation with novel machine learning architectures.
- Deployment of machine learning models in production environments.
Real-World Example
Tesla utilizes PyTorch for developing its autonomous driving software, leveraging the framework’s flexibility to build and train complex neural networks for real-time decision-making.
6. XGBoost & LightGBM
What They Are
XGBoost (Extreme Gradient Boosting) and LightGBM (Light Gradient Boosting Machine) are powerful gradient boosting frameworks designed for efficient and scalable machine learning. XGBoost, developed by Tianqi Chen, is renowned for its performance and speed, while LightGBM, developed by Microsoft, is optimized for faster training speed and lower memory usage.
Why They Matter in 2025
Both libraries have become staples in the machine learning community due to their ability to handle large-scale data and deliver high performance:
- Efficiency: LightGBM uses histogram-based algorithms, leading to faster training and reduced memory consumption.
- Accuracy: XGBoost incorporates regularization techniques to prevent overfitting, enhancing model generalization.
- Scalability: Both support parallel and distributed computing, making them suitable for big data applications.

Use Cases in AI & Data Science
- Fraud detection in financial transactions.
- Customer churn prediction in telecom industries.
- Sales forecasting in retail sectors.
- Risk assessment in insurance underwriting.
Learn more about the benefits of LightGBM here.
Real-World Examples
- XGBoost: A study utilized XGBoost to predict house prices, demonstrating its superior performance over other algorithms in terms of accuracy and computational efficiency.
- LightGBM: DoorDash employed LightGBM for forecasting delivery times, leveraging its speed and accuracy to enhance customer satisfaction.
7. Hugging Face Transformers
What It Is
Hugging Face Transformers is an open-source library providing a vast collection of pre-trained models for natural language processing (NLP), computer vision, and audio tasks. It offers seamless integration with PyTorch and TensorFlow, facilitating easy deployment of state-of-the-art models.
Why It Matters in 2025
The library has revolutionized the way developers approach machine learning tasks:
- Accessibility: Provides user-friendly APIs to implement complex models with minimal code.
- Versatility: Supports a wide range of tasks, including text classification, translation, and question answering.
- Community Support: A vibrant community contributes to a continuously growing repository of models and datasets.
Use Cases in AI & Data Science
- Developing chatbots for customer service.
- Automated content moderation on social media platforms.
- Sentiment analysis for market research.
- Language translation services.
Find out more about Hugging Face Transformers and explore its communities here.
Real-World Example
Hugging Face Transformers were utilized to develop a system for detecting hate speech in social media posts, significantly improving the accuracy and efficiency of content moderation processes.
8. Polars
What It Is
Polars is an open-source DataFrame library designed for high-performance data manipulation and analysis. Written in Rust, it offers a fast and efficient alternative to traditional libraries like pandas, especially for large-scale data processing tasks.
Why It Matters in 2025
Polars has gained significant traction due to its performance and scalability:
- Speed and Efficiency: Polars leverages multi-threaded execution and a columnar memory layout, resulting in faster computations and lower memory usage compared to pandas. Benchmarks have shown that Polars can be up to 10 times faster than pandas for certain operations.
- Lazy Evaluation: Polars supports lazy evaluation, allowing it to optimize query execution plans and reduce unnecessary computations.
- Cross-Language Support: While primarily used with Python, Polars also offers APIs for languages like R and Node.js, broadening its applicability.

Use Cases in AI & Data Science
- Large-Scale Data Analysis: Processing datasets that exceed system memory capacity.
- Feature Engineering: Efficiently transforming and preparing data for machine learning models.
- Real-Time Data Processing: Handling streaming data for applications requiring low-latency computations.
Real-World Example
Polars has been utilized in various industries for its performance benefits. For instance, in financial services, companies have adopted Polars to process large volumes of transaction data efficiently, enabling faster analytics and decision-making processes.
9. LangChain
What It Is
LangChain is an open-source framework designed to simplify the development of applications powered by large language models (LLMs). It provides tools and abstractions for building complex AI applications, such as chatbots, question-answering systems, and agents that can interact with various data sources.
Why It Matters in 2025
LangChain has become a cornerstone in the AI development ecosystem due to several factors:
- Modular Architecture: LangChain’s design allows developers to easily integrate different components, such as LLMs, vector databases, and APIs, facilitating rapid prototyping and deployment.
- Extensive Integrations: It supports a wide range of integrations with popular tools and services, enhancing its versatility in various applications.
- Community and Ecosystem: A vibrant community contributes to the continuous evolution of LangChain, ensuring it stays up-to-date with the latest advancements in AI.
Use Cases in AI & Data Science
- Conversational Agents: Building chatbots and virtual assistants that can understand and generate human-like responses.
- Document Analysis: Creating systems that can summarize, extract, and analyze information from large volumes of text.
- Data Integration: Developing applications that can interact with various data sources, such as databases and APIs, to retrieve and process information.
Real-World Example
LangChain has been employed in the development of mental health chatbots that provide support and resources to individuals. These applications leverage LangChain’s capabilities to understand user inputs and deliver contextually relevant responses, demonstrating its potential in sensitive and impactful domains.
10. Matplotlib & Seaborn
What They Are
Matplotlib is a foundational Python library for creating static, animated, and interactive visualizations. It offers extensive control over plot elements, making it suitable for detailed customization.
Seaborn builds on top of Matplotlib, providing a high-level interface for creating attractive and informative statistical graphics. It simplifies complex visualizations and integrates closely with pandas data structures.

Why They Matter in 2025
Both libraries continue to be indispensable tools for data visualization:
- Matplotlib:
- Supports a wide range of plot types, including line, bar, scatter, histogram, and more.
- Highly customizable, allowing for precise control over every aspect of a plot.
- Integrates seamlessly with other libraries like NumPy and pandas.
- Seaborn:
- Offers built-in themes and color palettes for aesthetically pleasing plots.
- Simplifies the creation of complex visualizations like heatmaps, violin plots, and pair plots.
- Provides functions that operate directly on DataFrames, streamlining the plotting process.
Recent updates have enhanced their capabilities:
- Seaborn‘s latest release focuses on causal inference visuals, such as difference-in-difference plots and propensity score distributions, making it a favorite among social science researchers.
- Matplotlib has improved its integration with accessibility tools, allowing for better support in generating alt text for figures, enhancing inclusivity in data presentations.
Use Cases in AI & Data Science
- Matplotlib:
- Creating detailed plots for data exploration and presentation.
- Developing custom visualizations for specific analytical needs.
- Integrating plots into applications and dashboards.
- Seaborn:
- Performing exploratory data analysis with statistical visualizations.
- Visualizing relationships and distributions in datasets.
- Generating publication-quality graphics with minimal code.
Real-World Example
In a case study, Matplotlib was used to analyze stock price trends, creating line charts to visualize fluctuations over time. Seaborn complemented this by generating heatmaps to identify correlations between different financial indicators, providing comprehensive insights into market dynamics.
Navigating the Evolving Python Ecosystem in 2025
As we progress through 2025, Python continues to be the cornerstone of data science and AI development. Its rich ecosystem of Python libraries empowers developers and organizations to build robust, scalable, and innovative solutions. From foundational tools like NumPy and pandas to advanced frameworks like TensorFlow and PyTorch, the Python landscape offers a comprehensive suite for tackling diverse challenges in data analysis, machine learning, and AI.
Emerging Python libraries such as Polars and LangChain are pushing the boundaries of performance and flexibility, delivering capabilities tailored for modern data workflows and intelligent applications. Meanwhile, tools like MLflow are simplifying the Python machine learning lifecycle, enabling better reproducibility, collaboration, and deployment.
At Fyld, we remain committed to harnessing the full potential of the Python ecosystem to deliver data-driven solutions that drive business value. Our expertise in integrating these libraries into cohesive Python-based workflows ensures our clients stay competitive in an increasingly complex tech landscape.
Whether you’re a seasoned Python developer, a data scientist, or just starting your AI journey, staying informed about the latest in Python for AI and data science will equip you with the tools and insight needed to succeed in 2025 and beyond.


